SRF Teletext Parsing with txtv
I spent some time with a neat little CLI application: txtv
This app written in Python let's you easily read latest Swedish Teletext news. It's “a client for reading swedish text tv in the terminal”.
I slightly modified the code so it reads from Swiss 🇨🇭 Teletext source (SRF):
https://github.com/voidcase/txtv/pull/15
I could figure out the URL for the API by observing how the .gif pictures for the teletext.ch website are generated from the API while browsing through the txt pages:
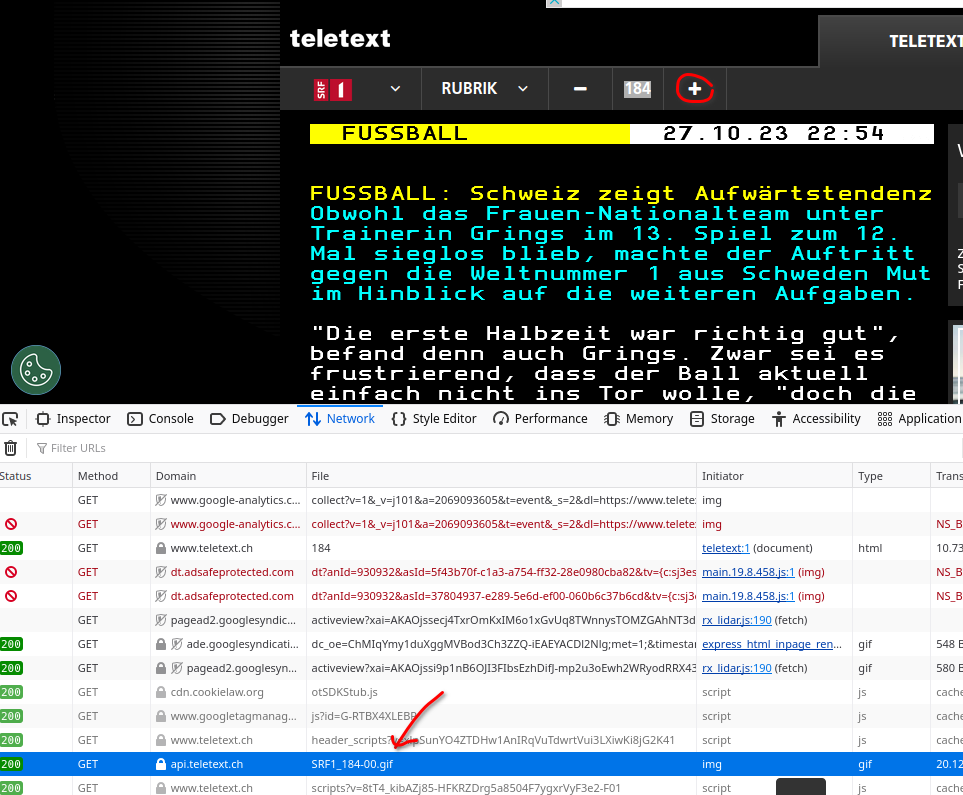
- https://www.teletext.ch
https://api.teletext.ch/channels/SRF1/pages/{num}
Unfortunately, I did not find a proper documentation for this API 😢.
Reading a bit of Javascript in the browser debugging console helped me to figure out the path structure of the https://api.teletext.ch API a bit better.
By the way, on my mobile I typically read https://m.txt.ch/SRF1 (but this one does not really work well for reading on the web browser / Laptop).
After playing a while with the API I realized, that there is not really an easy way to parse the structure of such a txt page from specific API fields.
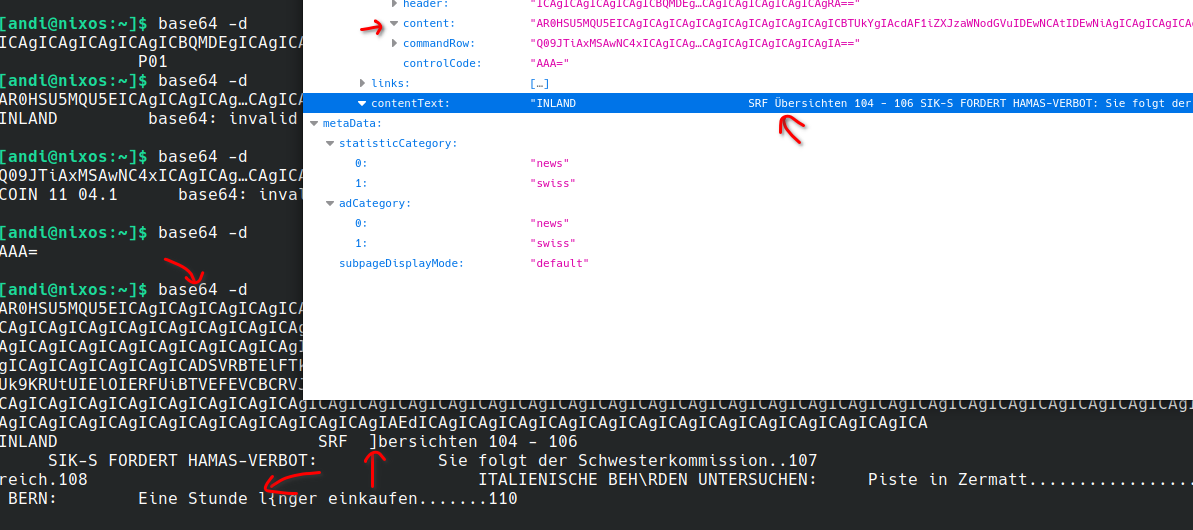
I decided to only use the content field, because it already displays the Swiss German special characters and Umlauts quite well. Also, the header and other fields like commandRow where not really helpful to parse the content on a page (e.g., to substract title text):
curl -s https://api.teletext.ch/channels/SRF1/pages/130 | jq -r '.subpages[0].ep1Info.data.ep1Format.header'
ICAgICAgICAgICAgICBQMDEgICAgICAgICAgICAgICAgICAgICAgRA==
curl -s https://api.teletext.ch/channels/SRF1/pages/130 | jq -r '.subpages[0].ep1Info.data.ep1Format.header' | base64 -d
P01 D
In Teletext the pages generally follow a specific structure, most of the time.
Generally, there are some overview pages with links to subpages. The actual content can then be explored on these subpages.
The txtv CLI also roughly supports these two types of pages.
By default, txtv starts in the “interactive mode”, when not started with a specific argument (e.g., to read a specific page nr):
[andi@nixos:~]$ txtv
WHO: Kontakt nach Gaza gestört.......133
UNO bestätigt Gaza-Resolution........134
Maine: Mutmasslicher Schütze tot.....140
Frauen-Nati unterliegt Schweden......183
Lugano siegt bei ZSC Lions...........187
05:05 Gredig direkt/UT...............734
05:40 Hoch hinaus/UT.................735
06:25 News-Schlagzeilen 07:30 Wetterkanal KURZÜBERSICHT101
INLAND...............................104
SPORT................................180
AUSLAND..............................130
METEO................................500
WIRTSCHAFT...........................150
TV&RADIO.............................700
Very nice 😎 Not perfect, but still useful.
Now, for my patch I concentrated on displaying the information on two pages:
INLAND 104AUSLAND 130
I also did some parsing regarding the “TV&RADIO” section but gave up on over-engineering that part after some time 🤓.
[andi@nixos:~]$ txtv 104
Sie folgt der Schwesterkommission....107
Aktionsplan Schweiz und Frankreich...108
Piste in Zermatt.....................109
Eine Stunde länger einkaufen.........110
[andi@nixos:~]$ txtv 130
WHO: Kein Kontakt zu Mitarbeitenden..133
UNO-Vollversammlung Gaza-Resolution..134
Reaktionen auf UNO-Resolution........135
Gaza: Kein Internet nach Angriffen...136
Weitere Hilfsgüter für Gazastreifen..137
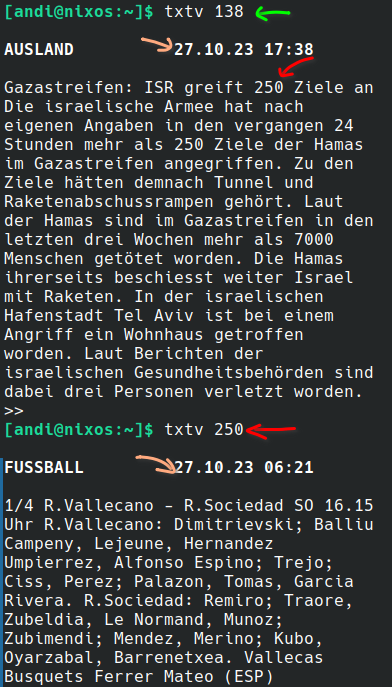
Israel greift........................250
Hamas-Ziele an.......................138
Unesco fordert Schutz der Schulen.. 139MAINE/USA: Polizei findet Leiche140
As you can see from the examples above, the parsing rules still have some issues. This is due to the fact that I can only rely on a few basic assumptions on how the overview txt pages (e.g., 104 and 130) are structured. For instance, the current parsing is flawed when a page title includes a three digit number. For example “Israel greift 250 Hamas-Ziele an”:
Israel greift........................250
Hamas-Ziele an.......................138
The problem here is that 250 is interpreted as a page number, where it should not.
Unfortunately, I'm not aware of a solution for this, except for finding a smarter parsing rule:
# Find all three digit numbers, most probably these are page numbers
page_nrs = re.findall(r'\s(\d{3})*[-\/]*(\d{3})([^\d]|$)', stories)
all_page_nrs = []
for p in page_nrs:
try:
n = int(p[0])
all_page_nrs.append(n)
except:
pass
try:
n = int(p[1])
all_page_nrs.append(n)
except:
pass
all_page_nrs = [str(p) for p in all_page_nrs]
I experimented with quite a few variations, but gave up after some time, because each has it's benefits and pitfalls, where the rule would help in some cases but perform worse in another edge case.
So, if you have any suggestions on how to solve that problem of “missing intent” while parsing basically “generic text” let me know. I heard that in this age of AI and machine learning we should be able to do better, shouldn't we?
The same problem also applies when parsing the titles and subtitles on the overview pages. The txtv ls command is my favorite command. It simply lists all the subpages of the pages 104 (INLAND) and 130 (AUSLAND):
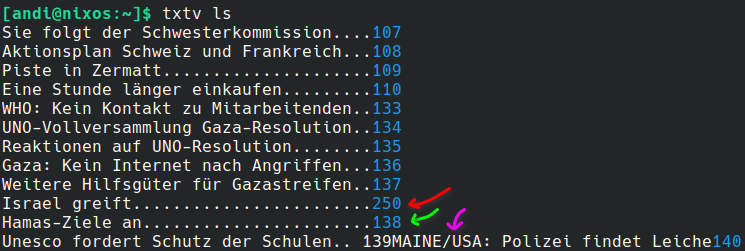
But here, as well, my parsing rule is flawed when it comes to actual page titles containing more than a few capital letters in a row (3-4 capital chars are typically used for abbreviations):
if self.num == 100 or self.num == 700:
# Remove actual titles
stories = re.sub("Jetzt auf SRF 1", "", stories)
stories = re.sub("JETZT AUF SRF 1", "", stories)
stories = re.sub("TELETEXT SRF 1", "", stories)
else:
# Remove all uppercase subtitles. There can be multiple
# subtitles on a page (subtitle, stories, subtitle, stories, etc)
stories = regex.sub(r'[\p{Lu}\s-]{9,}[\s:]', '', self.content)
So in generally I can be quite happy with the outcome. It gives me a fast and smart way to quickly read the news on any terminal enabled device with Internet access 🤓. Also, the parsing rules on the individual detail/content/sub pages to extract the category and date work flawlessly (except maybe for the more special pages/categories like SPORT and TV&RADIO).
For future improvements I'm right now thinking to also use the links of the API output for extracting the set of real page numbers, which would at least help me with the first problem presented in this article (the titles that contain three digits):
curl -s https://api.teletext.ch/channels/SRF1/pages/130 | jq -r '.subpages[0].ep1Info.links'
For any page without links, I could simply apply the “content page” rendering which has shown to work pretty well already.